Agency Second Brain: The Vault Architecture
Applying the second brain pattern to an agency's operational context.
This is a follow-up to Building a Second Brain with Claude Code. That piece covered the personal system — how I use Obsidian, Claude Code, and a structured Markdown vault to give an AI persistent context across sessions. This one covers what happened when I recognized the same problem at work, at a larger scale, with other people's clients in the mix.
A few weeks after I built my personal second brain, I was sitting in a client call prep session at work.
I manage client success and growth strategy at AutoBoost, a digital marketing agency for auto repair shops. Before every client review, the account manager needs context: what was discussed last month, how the current campaigns are performing against goal, what's still open from the last call, how this particular client likes to communicate. It's not complicated information. But it lives in HubSpot call logs, in Slack threads, in someone's memory of a conversation three weeks ago.
I watched someone spend twenty minutes reconstructing that context before a thirty-minute call.
And I thought: this is the same problem I just solved for myself. But worse, because it's not one person's context. It's 400 clients, managed by multiple account managers, each with their own working style and communication patterns. And now we're trying to use AI to draft emails, generate meeting prep documents, and pull performance summaries, and every session starts fairly cold.
The output was never bad enough to be obviously broken. We still use the built-in memory tools and project contexts provided by Frontier Labs. It was just consistently off. Generic where it should be specific. Formal, where this client expected casual. Missing the context about what happened on the last call because nobody told the model about the last call.
The problem isn't the model. It's that nobody built the environment the model needs to do the work well.
The Same Root Cause
In the personal system, I described this as context amnesia: the AI starts every session with no memory of who you are, what you're building, or what happened last time, or a very limited sense if you have a subscription which gives your agent access to memory or the ability to search chat history. You solve it by giving the model a structured environment to read before it acts.
At the agency level, the problem is identical: just multiplied by hundreds of clients and several account managers, and complicated by the fact that the context lives across multiple people instead of one.
The solution I built at work is what I now call an operational vault. It borrows everything from the personal second brain pattern: a directory of Markdown files, a CLAUDE.md operating contract, an INDEX.md catalog, and a LOG.md audit trail. The key difference is what it's designed for. The personal second brain is a knowledge base I query. The operational vault is an environment that agents read before they do something.
That distinction turned out to matter a lot.
The Architecture
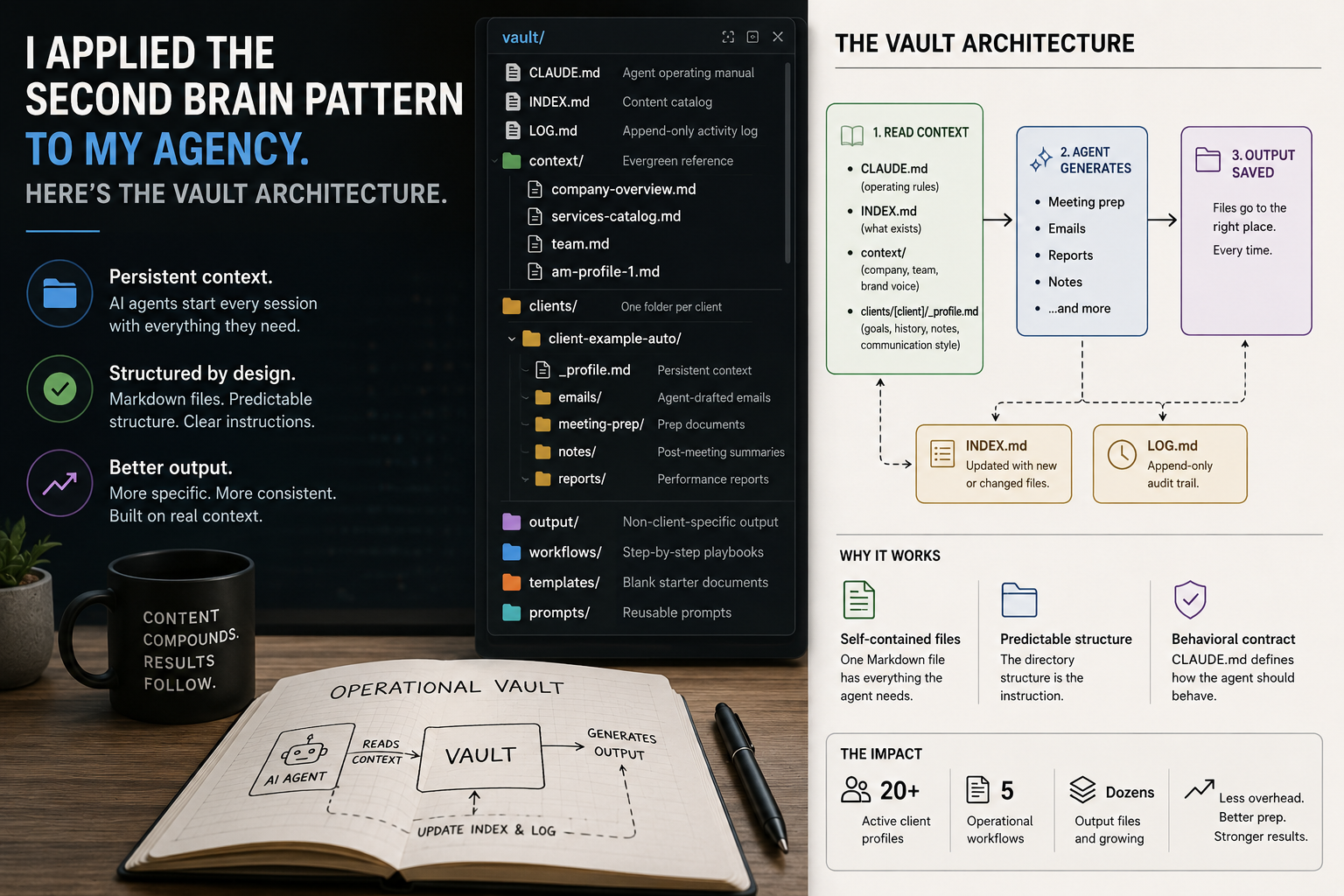
The vault is a directory of plain Markdown files — compatible with Obsidian, operable by any AI coding agent that can read a filesystem.
vault/
├── CLAUDE.md ← Agent operating manual
├── INDEX.md ← Content catalog
├── LOG.md ← Append-only activity log
│
├── context/ ← Evergreen reference — agents read this first
│ ├── company-overview ← Brand voice, services, mission
│ ├── services-catalog ← Full service offering descriptions
│ ├── team ← Team members, roles, communication style
│ └── am-profile-1 ← Working style and tone for an account manager
│
├── clients/ ← One subfolder per client
│ └── [client-slug]/
│ ├── _profile.md ← Persistent context: goals, notes, service history
│ ├── emails/ ← Agent-drafted emails ready to send
│ ├── meeting-prep/ ← Prep documents
│ ├── notes/ ← Post-meeting summaries
│ └── reports/ ← Performance reports
│
├── output/ ← Non-client-specific output
├── workflows/ ← Step-by-step playbooks for recurring processes
├── templates/ ← Blank starter documents
└── prompts/ ← Reusable system instructions or prompts for agents & assistants that are outside of this ecosystem
Three things make this different from a shared wiki or a CRM.
The files are self-contained. Each client profile is a single Markdown document. An agent reads it in one pass and has the full picture — not a UI that requires clicking into related records, not an API that needs multiple calls to assemble context. One file. Everything the agent needs to act.
Output directories are predictably named. When an agent generates a deliverable, it knows where the file belongs. The directory structure is the instruction. No human has to route the output.
CLAUDE.md is a behavioral contract, not a description. It tells the agent what good output looks like, what naming convention to use, when to flag missing context instead of inventing it, and how to maintain the index and log after every operation. An agent that reads this file before acting knows how to behave in the vault without additional instruction.
The Two Navigation Primitives
I borrowed these directly from the personal system, and they matter just as much here.
INDEX.md is a catalog of every file in the vault — what it is, what it contains, where it lives. The agent reads this before searching. At twenty-something client profiles plus dozens of output files, this is what keeps sessions efficient. The agent knows what exists without crawling directories.
LOG.md is append-only. Every significant action gets a timestamped entry: what context was read, what was generated, what changed. It's the audit trail. It also answers the question that comes up constantly at the agency level: when was this drafted, and what did we know at the time?
What This Looks Like Running
Here's the monthly client review prep workflow, which is where I first validated that the architecture actually worked.
The account manager triggers the task. The agent reads CLAUDE.md first — the operating rules. Then INDEX.md — what context exists in the vault. Then context/company-overview.md — brand voice and service framing. Then clients/[client]/_profile.md — that client's goals, service history, notes from previous calls, and how the account manager has communicated with them before.
From that reading, the agent generates the meeting prep document. Talking points in the first person, in the account manager's voice. Performance metrics cited specifically — not "results improved" but actual numbers. The meeting goal woven into the agenda rather than bolted on at the top.
The file goes into clients/[client]/meeting-prep/ with a standardized filename. INDEX.md gets updated. LOG.md gets an entry.
The account manager opens the file, reviews it, and is ready for the call.
No prompting about who the client is. No re-explaining brand voice. No reformatting before it's usable. The agent knew what to do because the vault told it.
What Changed
A few things I didn't fully anticipate.
Output quality became consistent in a way that prompting never delivered. Prompting gets the model oriented for one session. The vault keeps it oriented across every session. The difference shows up in specificity — a document generated from a rich client profile reads differently than one generated from a good system prompt.
The context-setting overhead disappeared. This is the one I noticed most immediately. The twenty minutes of context reconstruction before a client call — reading back through HubSpot, refreshing on last month's discussion, remembering the account manager's notes — that work moved into the vault, where it accumulates after each call instead of being rebuilt before each call.
The log became unexpectedly useful as a management artifact. I can look at the log and see what was drafted, when, by whom, and what context was available at the time. That's not something a shared Google Drive gives you.
At the time of writing, the vault holds over twenty active client profiles, workflows for five recurring operational processes, a full technical operations manual for the engineering team, and dozens of output files.
The Pattern and Where It Goes
The personal second brain and the operational vault are the same underlying architecture. CLAUDE.md as the operating contract. INDEX.md as the catalog. LOG.md as the audit trail. Markdown files designed to be read by AI agents before they act.
The personal system is designed for one person to query. The operational vault is designed for agents to work. That's the fork in the pattern — and it's a meaningful one.
What I've been thinking about since: the vault pattern scales horizontally in a way the personal system doesn't. A single well-structured _profile.md for each client is more durable and more useful than any amount of prompting. The index and log compound. The context gets richer every time someone adds a call note or a performance report. Six months from now, the vault knows the client better than any individual team member does.
I don't think this is specific to marketing agencies. Any team using AI for client-facing work — consulting, law, financial advising, real estate — has the same underlying problem. The agents don't know who the clients are. Nobody built the environment they need.
That's still mostly true. But it doesn't have to be.
The architecture described here is built on plain Markdown files, compatible with Obsidian and operable by Claude Code or any AI coding agent with filesystem access. The CLAUDE.md pattern originated with Andrej Karpathy.